Nov 2021
A static site generator using Django, Wget and Github Pages
If you're a Django developer and want to publish a website without the hassle (and costs) of deploying a web app, then this post may give you some useful tips.
I found myself in this situation several times, so I've created a time-saving workflow and set of tools for extracting a dynamic Django website into a static website (i.e., a website that does not require a web application, just plain simple HTML pages).
Disclaimer: This method is not suited for all types of websites. For example, if your Django application is updated frequently (e.g., more than once a day), or if it has keyword search (or faceted search) pages that inherently rely on dynamic queries to the Django back-end based on user input, then a static site won't cut it for you, most likely.
In a nutshell, this is how it works:
- On my computer, I create and edit the website contents using Markdown as much as I can—i.e., text files.
- Markdown files are transformed to HTML using a Django (Python) application, which runs on
localhostand is used to review and style these pages. - Finally, I use the almighty wget to extract the website HTML into a standalone static site that I can easily publish online, e.g., by syncing it to GitHub Pages or any of the other free hosting services for static sites.
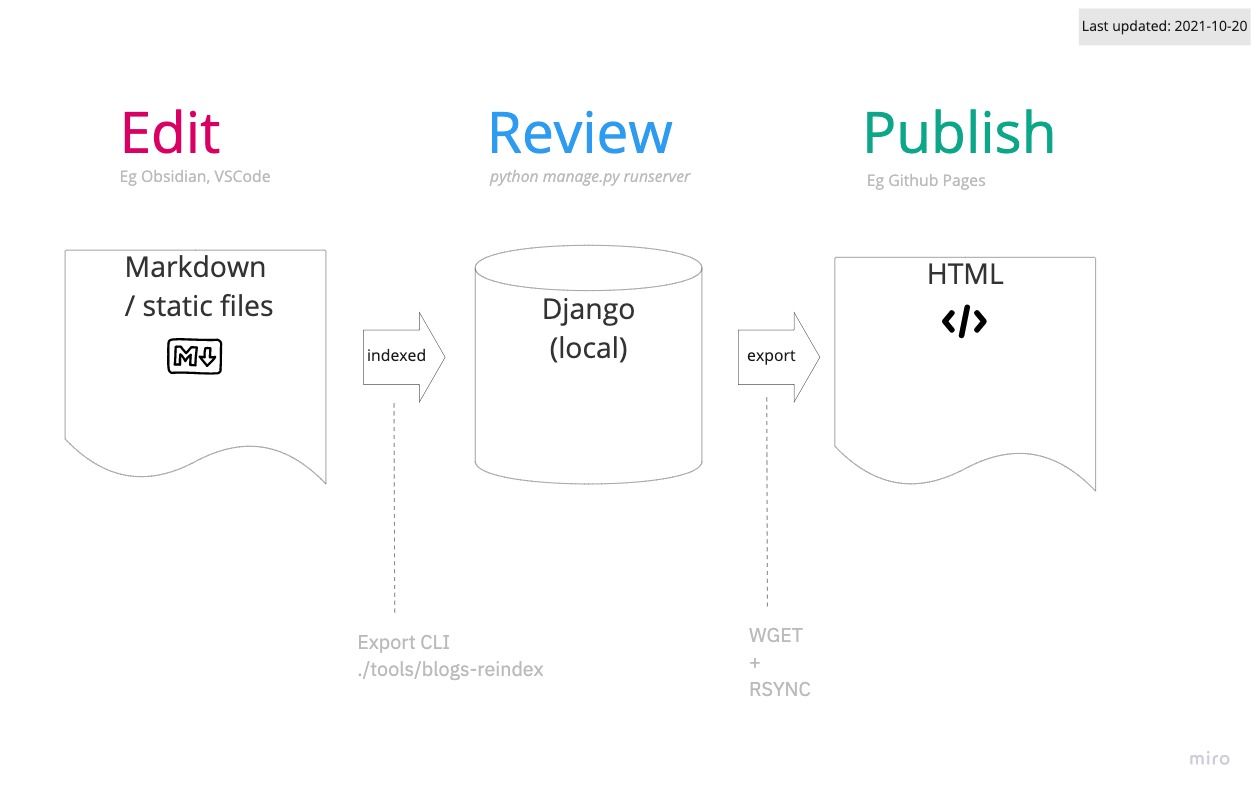
All of the steps happen on your local computer. Keep reading to find out more about each of these steps.
1. Editing
It's useful to think of a concrete use case, so I'll be talking about my personal site www.michelepasin.org (the site you're on right now), which happens to be the first site I've published following this method.
My website has generally two types of pages:
- Static text pages created from Markdown files, e.g., a blog post.
- Dynamic HTML pages created from metadata stored in the database, e.g., a project description page.
Static pages
For the static text pages, I basically have a folder on my computer full of Markdown files, which I can edit using any text editor I want. For example, lately I've been using Obsidian (screenshot below) for taking notes and editing Markdown documents. It's excellent (see this review). So I keep all the blog posts in a folder (outside the Django app) that is monitored by Obsidian (a "vault"—that's what Obsidian calls it).
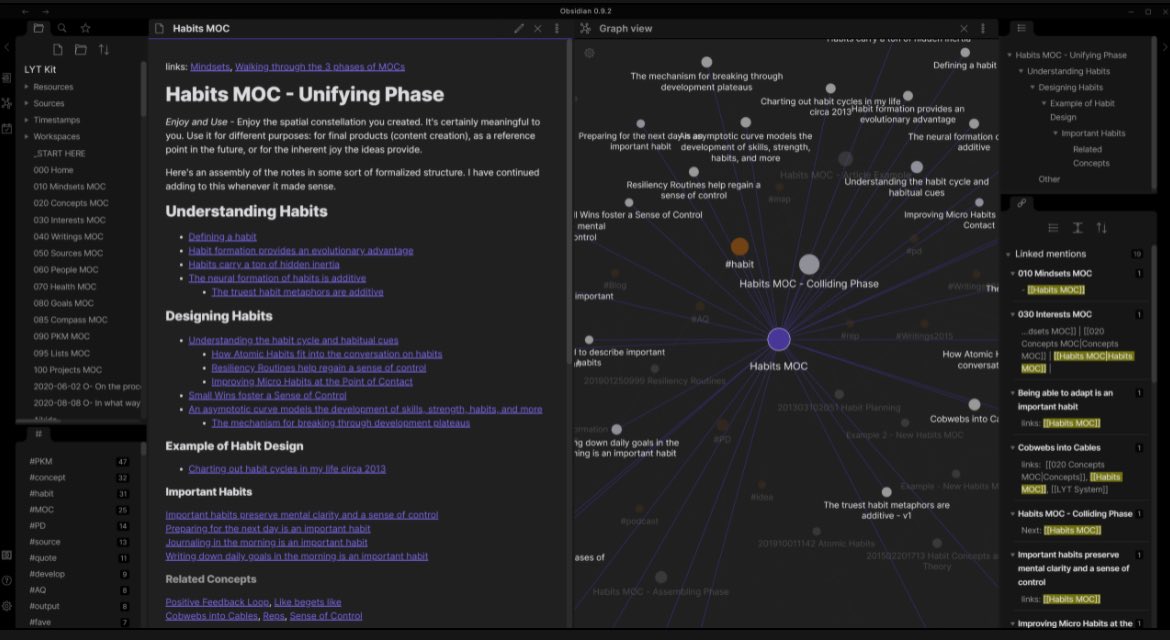
As a result, I can make use of Obsidian's advanced Markdown editing features.
Plus, it fits nicely into my daily routine because the posts live alongside other daily notes that are not meant for sharing. This is super cool because I have my entire blog archive accessible in my note-taking app, which kind of blurs the line between published notes and private notes.
Dynamic pages
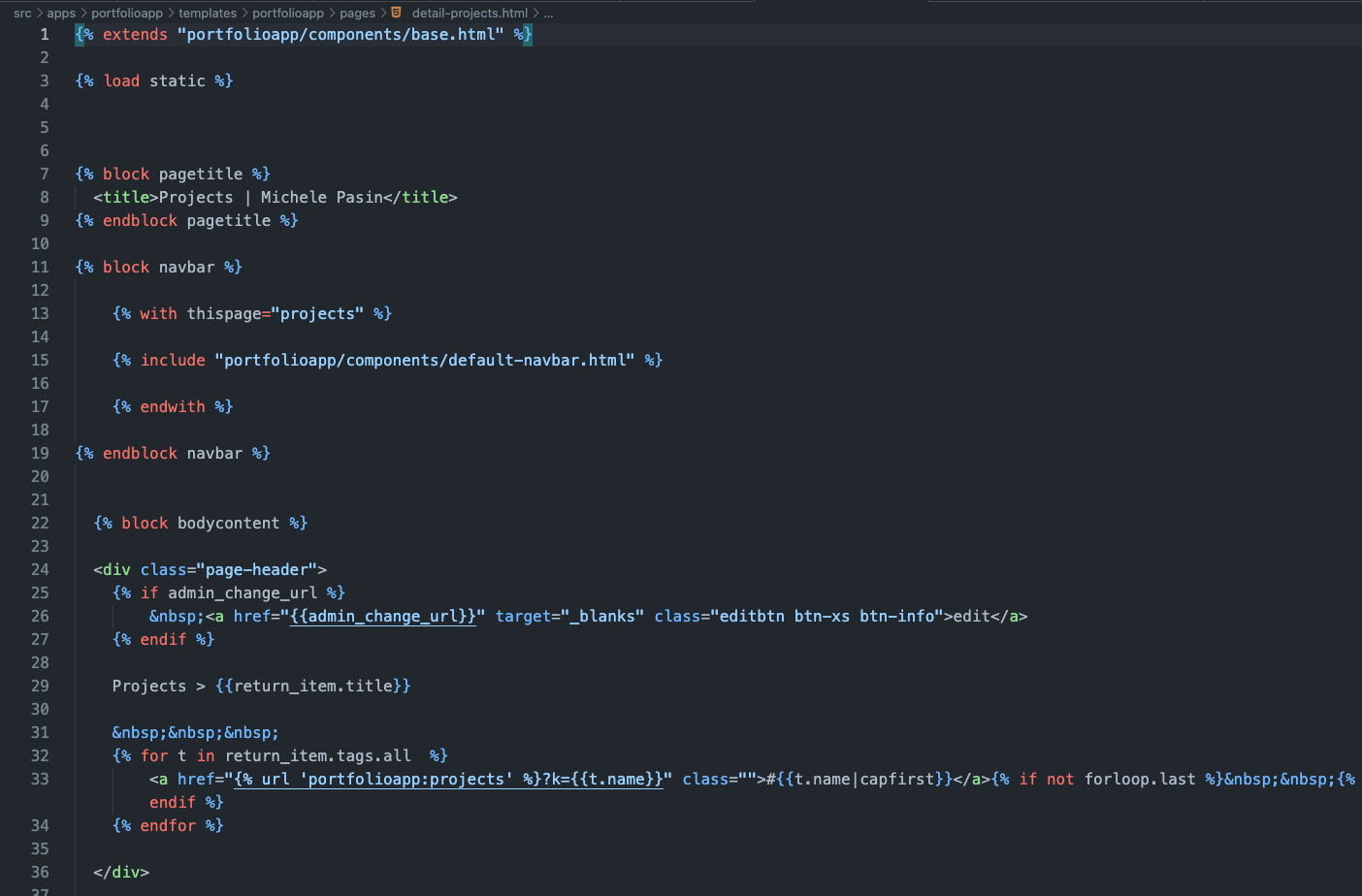
For the dynamic pages, I just use the good old Django templates (the usual Django way of doing things).
There's nothing new here—if you are a Django developer, you'd know immediately what I'm talking about. HTML, template tags, etc.
Conclusion
This approach allows me to have a clean separation between content I need a database for—that is, content I want to catalog and organize methodically (e.g., projects, papers, etc.)—and other textual content that I'd rather edit outside the web app, for example using my text editor of choice.
So, in a nutshell
- Creating/editing a blog post → Obsidian, using a pre-defined folder
- Creating/editing other pages → Django HTML templates
2. Rendering/Reviewing
The Django web app is where things come together. The idea is that you run the Django app as usual and see the results on localhost.
$ python manage.py runserver
The interesting bit has to do with how the Markdown/static text pages get integrated into the website. There are two parts: Markdown indexing and Markdown rendering.
Markdown indexing
A command-line script creates an index of all the Markdown files (in the blog posts folder). This index is basically a collection of metadata about these files (e.g., title, publication date, tags, file location on the computer), which get stored in the Django back-end database.
As a result, this metadata can be used by the Django web app to retrieve, search, and filter the Markdown files via the usual model-view-controller machinery Django provides.
Here is a sample run of the interactive script, called blogs-reindex:
$ ./tools/blogs-reindex
+++++++++++++++++
REFRESHING BLOGS INDEX...
+++++++++++++++++
Environment: local
DEBUG:True
+++++++++++++++++
Reading... </Users/michele.pasin/markdonw/Blog/>
=> Found new markdown file: 2021-10-29-django-wget-static-site.md.
Add to database? [y/N]: y
=> Created new obj: {pub}
# Files read: 340
# Records added: 1
# Records modified: 0
Cleaning db...
# Records in db : 340
# Markdown files: 340
----------
Done
See the full source code on GitHub.
Markdown rendering
The second part of this architecture simply consists of the Python functions that transform Markdown into HTML. Of course, that follows the usual Django pattern—i.e., a url controller and related view functions that know how to handle the Markdown format:
#
# in settings.py
#
BLOGS_ROOT = "/path/to/my/markdown/blog/"
#
# in views.py
#
def blog_detail(request, year="", month="", day="", namedetail=""):
"""
Generate the blog entry page from markdown files
"""
context = {}
permalink = f"""{year}/{month}/{day}/{namedetail}"""
return_item = get_object_or_404(Publication, permalink=permalink)
# get the contents from the source MD files
# NOTE the filepath is stored in the `md_file` field
TITLE, DATE, REVIEW, PURE_MARKDOWN= parse_markdown(BLOGS_ROOT +
return_item.md_file)
html_blog_entry = markdown.markdown(PURE_MARKDOWN,
extensions=['fenced_code', 'codehilite'])
context = {
'return_item' : return_item,
'admin_change_url' : admin_change_url,
'blog_entry': html_blog_entry,
}
templatee = "detail-blogs.html"
return render(request, APP + '/pages/' + templatee, context)
#
# in urls.py
#
url(r'^blog/(?P<year>[\w-]+)/(?P<month>[\w-]+)/(?P<day>[\w-]+)/(?P<namedetail>[\w-]+)/$', views_pubs.blog_detail, name='blogs-detail'),
The code above uses the python-markdown library to transform Markdown text to HTML. For more details, see the source code of the parse_markdown function.
3. Publishing
The final step is publishing the website online. For this, I'm using Wget to generate a static version of the site and GitHub Pages to make it available online at no cost.
This is done via another command-line script: ./tools/site-dump-and-publish. The command does four main things:
- Back up the previous version of the site.
- Use
wgeton the Django app running locally to pull all the site pages as a static website (note: hyperlinks must be "mirrored"). - Copy the static files to the
docsfolder (which I configured in GitHub Pages as the site source location). - Add/commit/push all changes to GitHub so that the new version of the site is live.
See the full command source code.
Here is a sample run:
$ ./tools/site-dump-and-publish
=================
PREREQUISITE
Ensure site is running on 127.0.0.1:8000...
=================
>>>>>>> DJANGO is RUNNING!
=================
=================
Dumping site..
=================
CREATE BACKUP DIRS in: backups/2021_10_28__05_31_49_pm/
+++++++++++++++++
BACKING UP SITE....RSYNC /DOCS TO /backups/2021_10_28__05_31_49_pm/docs
+++++++++++++++++
building file list ... done
...
... [OMITTED]
...
sent 101359148 bytes received 25982 bytes 40554052.00 bytes/sec
total size is 101243272 speedup is 1.00
BACKING UP DB DATA ....src/manage.py dumpdata TO /backups/2021_10_28__05_31_49_pm/data
+++++++++++++++++
Environment: local
DEBUG:True
+++++++++++++++++
DONE: backups/2021_10_28__05_31_49_pm/data/dump.json
BACKING UP MARKDOWN FILES from /Users/michele.pasin/Dropbox/Apps/NVALT/001/Blog TO /backups/2021_10_28__05_31_49_pm/md
+++++++++++++++++
DONE: backups/2021_10_28__05_31_49_pm/md
CLEAN UP TEMP BUILD DIR..
+++++++++++++++++
WGET SITE INTO TEMP BUILD DIRECTORY..
+++++++++++++++++
...
... [OMITTED]
...
FINISHED --2021-10-28 17:34:37--
Total wall clock time: 2m 44s
Downloaded: 878 files, 96M in 0.8s (120 MB/s)
RSYNC TEMP BUILD DIRECTORY INTO FINAL LOCATION: /docs
+++++++++++++++++
...
... [OMITTED]
...
sent 19574621 bytes received 17352 bytes 13061315.33 bytes/sec
total size is 101243252 speedup is 5.17
=================
Commit and push
=================
[master dd479c70] live site auto update
32 files changed, 1363 insertions(+), 49 deletions(-)
delete mode 100755 tools/data-dump
Enumerating objects: 220, done.
Counting objects: 100% (220/220), done.
Delta compression using up to 8 threads
Compressing objects: 100% (85/85), done.
Writing objects: 100% (116/116), 20.55 KiB | 1.37 MiB/s, done.
Total 116 (delta 63), reused 0 (delta 0), pack-reused 0
remote: Resolving deltas: 100% (63/63), completed with 51 local objects.
To https://github.com/lambdamusic/portfolio-site.git
8556da94..dd479c70 master -> master
Done
=================
About wget
GNU Wget is your friend. It's as old as the web (nearly—1996) and still one of the most powerful tools for extracting web pages.
Trivia:
In 2010, Chelsea Manning used Wget to download 250,000 U.S. diplomatic cables and 500,000 Army reports that came to be known as the Iraq War logs and Afghan War logs sent to WikiLeaks. (Wikipedia)
Here are some powerful options as described in the manual:
--mirror– Makes (among other things) the download recursive.--convert-links– Convert all the links (also to stuff like CSS stylesheets) to relative, so it will be suitable for offline viewing.--adjust-extension– Adds suitable extensions to filenames (htmlorcss) depending on their content type.--page-requisites– Download things like CSS stylesheets and images required to properly display the page offline.--no-parent– When recursing, do not ascend to the parent directory. It's useful for restricting the download to only a portion of the site.--no-host-directories– Disable generation of host-prefixed directories. By default, invoking Wget with-r http://fly.srk.fer.hr/will create a structure of directories beginning withfly.srk.fer.hr/. This option disables such behavior.--wait– Waiting time between calls. Set reasonable or random waiting times between two downloads to avoid the "Connection closed by peer" error.
About GitHub pages
I used GitHub Pages to host my static site, but there are many other no-cost options out there, e.g., GitLab or Netlify. So take your pick.
Of course, there are size limits too. For example, with GitHub Pages the maximum size for a repo (and hence a site) is 1 GB.
Also, there might be issues with how frequently you publish the site, although I've never run into any problem with that so far.
Wrapping up
In this post, I've shown how to turn a Django site into a static website so that it can be published online without the hassle (and costs) of deploying a web app.
Most likely, this method will resonate with Django developers primarily, but even if you're not, I'm hoping that some of these ideas can be easily transposed to other Python web frameworks.
Other options
I found a couple of other options online that allow turning a Django site into a static website. None of them worked for me, but they may for you, so they're worth having a look:
- django-freeze looks interesting, but it hasn't been updated for a while and doesn't work with Django >1.10 (I have 2.1.3).
- django-distill has lots of features, but it's way too complex for my needs because you have to define special URL controllers for the static pages you want to generate, which I didn't want to do or maintain.
Feedback and comments are welcome, here or on GitHub as usual!
Cite this blog post:
Comments via Github:
See also:
2022
International Conference on Science, Technology and Innovation Indicators (STI 2022), Granada, Sep 2022.
2019
Second biennial conference on Language, Data and Knowledge (LDK 2019), Leipzig, Germany, May 2019.
2017
paper Using Linked Open Data to Bootstrap a Knowledge Base of Classical Texts
WHiSe 2017 - 2nd Workshop on Humanities in the Semantic web (colocated with ISWC17), Vienna, Austria, Oct 2017.
2014
New Technologies and Renaissance Studies II, ed. Tassie Gniady and others, Medieval and Renaissance Texts and Studies Series (Iter Academic Press), Dec 2014. Volume 4
2012
2009